
The identity and access management platforms that I either used or researched in the past always left much to be desired. Most times their audit trails aren’t strong enough. Pricing per user or per session is too expensive. They don’t deploy easily in multiple regions. And they aren’t exactly easy to operate or scale across clouds.
There was clearly a gap in the market for a modern IAM platform. I needed such a platform in order to properly do my previous job as a Head of eGovernment and IAM (in Switzerland). But such a platform didn’t exist! This is when we began thinking through and building the platform that has become ZITADEL today. Jump straight to the architecture.
What is ZITADEL?
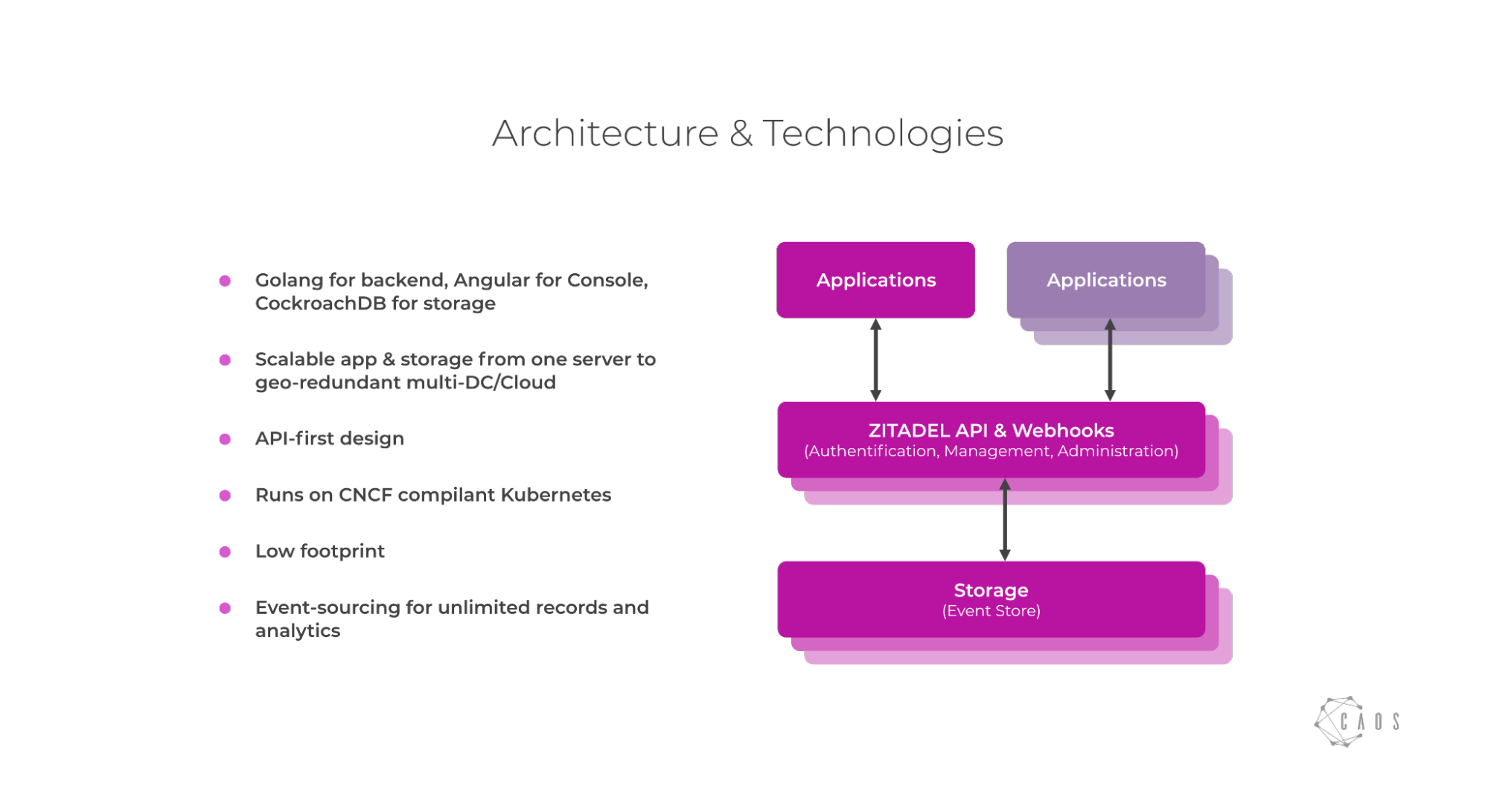
ZITADEL is a modern cloud-native IAM platform used by developers to integrate their authentication and authorization needs without the need for running their own code. There are different use cases for ZITADEL and different consumption models, and we have several differentiators like stronger audit trails, and ease of use, but in this blog I want to focus on how we built a scalable, cloud-native IAM platform that can scale across regions and across clouds.
Why do we rely on CockroachDB
We started the journey of building ZITADEL back in 2019 and one the biggest questions at that time was: which database could suit all our needs!? As we hypothesized that we want to build an ES system (Event Sourced), mainly to get a great audit trail embedded into the architecture, we came to the conclusion to use CQRS (Command Query Responsibility Segregation) as well. So we needed to evaluate which database could handle those two design patterns, while still being able to fulfill our requirements as listed below.
IAM Database Requirements:
-
Strong consistency for the eventstore
-
Great availability guarantees for our query databases
-
Cloud-native design
- Able to run on Kubernetes out of the box
- Horizontal scalability was a must
- Ability to run across multiple datacenters and regions
- Easy to automate
After an initial evaluation effort we settled with CockroachDB because it checked all our boxes. The most important checkbox being the fact that CockroachDB scales horizontally while still maintaining strong consistency. Moreover, storing our query side databases in the same cluster is a great plus - from an operational perspective - it is convenient not to have a service for each job. That would just make operations tricky and it enables our developers to focus on one battle-tested storage without the need to always reconsider where to store the data.
How we run ZITADEL and CockroachDB
At CAOS, the creator of ZITADEL, we are strongly committed to GitOps. We have written a blog in german and talked about that in the past. For us this means that each ZITADEL deployment gets its own Git Repository where all the required config and secrets (yes, they are encrypted) are stored. To aid with automating our lifecycle we created our project ORBOS.
With ORBOS we are able to declare and run hyper-converged ZITADEL clusters from scratch in about 20 minutes. As you can see in the graphic below ORBOS consists of two operators. ORBITER which takes care of lifecycling infrastructure components including Kubernetes and BOOM who manages the tools.
To deploy and lifecycle ZITADEL and CockroachDB we created a ZITADEL Operator which contains all the necessary operations logic to automatically operate ZITADEL. The operator carries out things like schema migrations for new ZITADEL versions, or backup and restore CockroachDB, manages the necessary client certificates to connect to CockroachDB, and so on.
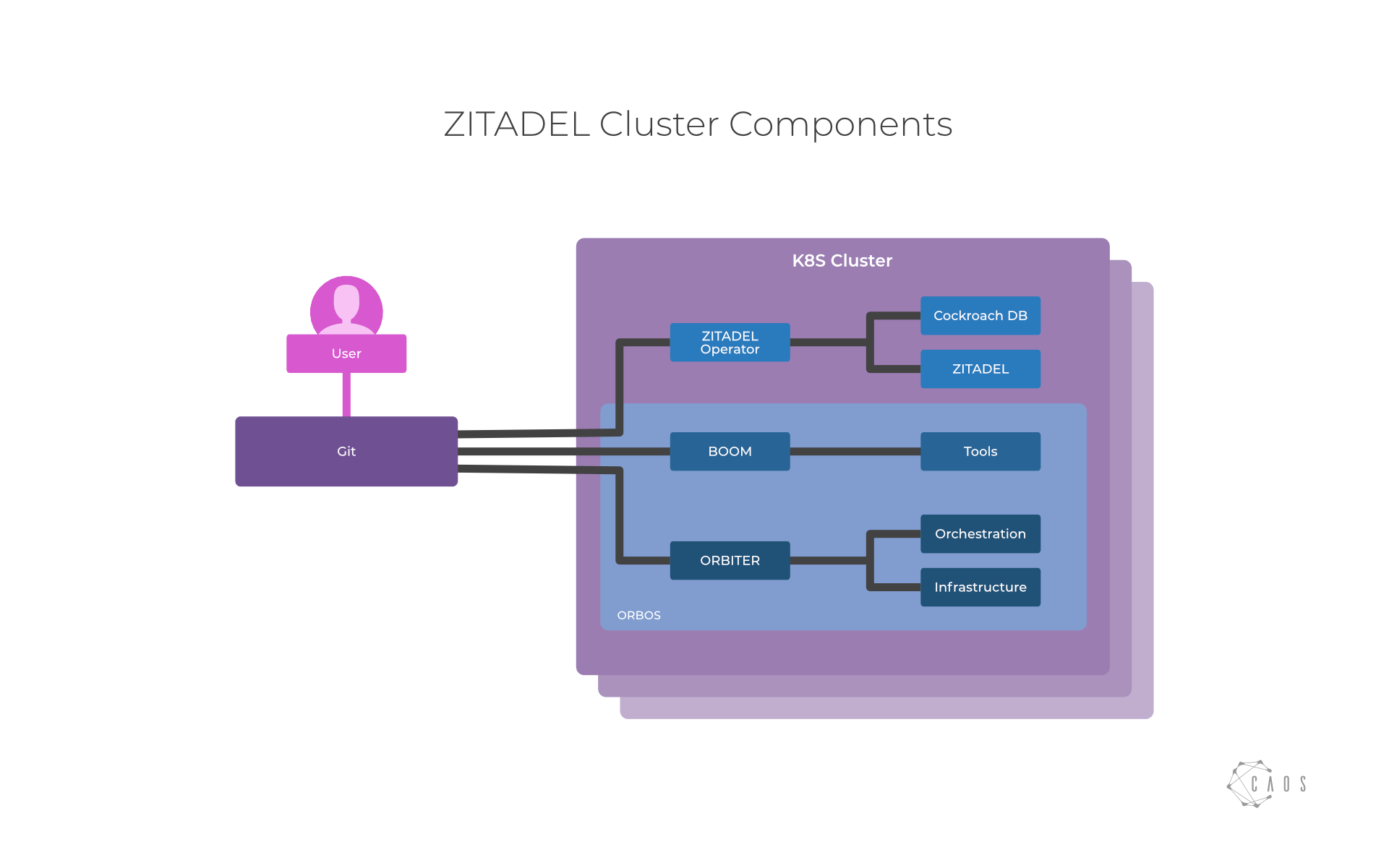
We are quite happy with this setup as it allows us to manage and run systems everywhere we like. And with GitOps we also have a great audit trail about our system changes.
Currently we run ZITADEL in parallel on GCP and Cloudscale, both providers with data centers in Switzerland.
Funny sidestory: ORBOS is used on its own as a Kubernetes platform by a lot of companies we work with. It even powers a government provider’s SaaS infrastructure.
The Challenge of Connecting Multiple Clouds
Still as of today one of the main challenges we face is the connection between multiple data centers. If you solely rely on one cloud provider this is not exactly a problem for you. Yet we decided early on that we wanted to run our cloud offering zitadel.ch across multiple providers to reduce any negative effect that one provider has – be it from an operational perspective like outages or from a risk standpoint. As we deal with sensitive data from our customers we wanted to reduce the risk of being too reliant on a single provider!
Today we connect different providers by utilizing good old IPSec VPNs as a means of transport. And for the Kubernetes connectivity we connect each cluster over the VPNs with BGP Peering and IPIP. However this does not scale well and tends to have quite some management overhead.
To connect the Cockroach databases located in each cluster we relied on this really useful blog from CockroachDB Gotchas & Solutions Running a Distributed System Across Kubernetes Clusters as we choose to use the DNS Chaining Method. But as we have full routing capabilities thanks to Project Calico we are able to send traffic over the overlay directly to each cluster’s DNS.

To solve the problems of the VPN overhead we are currently testing Cloudflare’s Magic WAN offering as a means to connect our data centers to a virtual WAN with a redundant GRE / IPSec connection. This would mean that we don’t need to build and maintain a mesh-style architecture for the east-west connectivity. The combination of CockroachDB and Magic WAN looks like a really powerful architecture.
If you don’t want the burden of managing that all on your own we can recommend CockroachDB Dedicated: A True Cloud Database!
The Future of Identity & Access Management
We think that CockroachDB is a great match to support our plans to continue building the most innovative Identity and Access Management platform. The two main features we think will enable us in the future are changefeeds and geo-partitioning.
Changefeeds could speed up the processing of backend processes which generate our query databases and also analytical things. We are currently thinking about running our events through machine learning to learn patterns to better mitigate attacks.
With geo-partitioning we aim to give our customers the ability to decide in which region they want to store their data. For example, today our systems only run in Switzerland but as we expand into the EU we would like to give our customers the option to say in which region their data is stored.
If you are interested in learning more about ZITADEL, head over to read Introduction to CAOS and ZITADEL Architecture. There’s also a detailed case study about our use of CockroachDB.
For those interested in the code visit caos/zitadel: ZITADEL - Cloud Native Identity and Access Management or caos/orbos: ORBOS - GitOps everything


